全站采集
{success} 全站采集简单使用场景: 大家采集搜狐。网易新闻 等大型门户网站。往往他的数据分类特别全,不说首页,门户网站一个2级频道的首页。下面有很多分类,每个小分类的数据也更新特别快。我们如果想要采集他的一个页面多个区块数据,对应到我们站点单个分类中,往往需要维护多个规则来对应我们站点一个分类,维护繁琐,全站采集可以帮助我们减轻负担。
{info} 全站采集,采集当前页面上所有符合我们要求的文章链接。
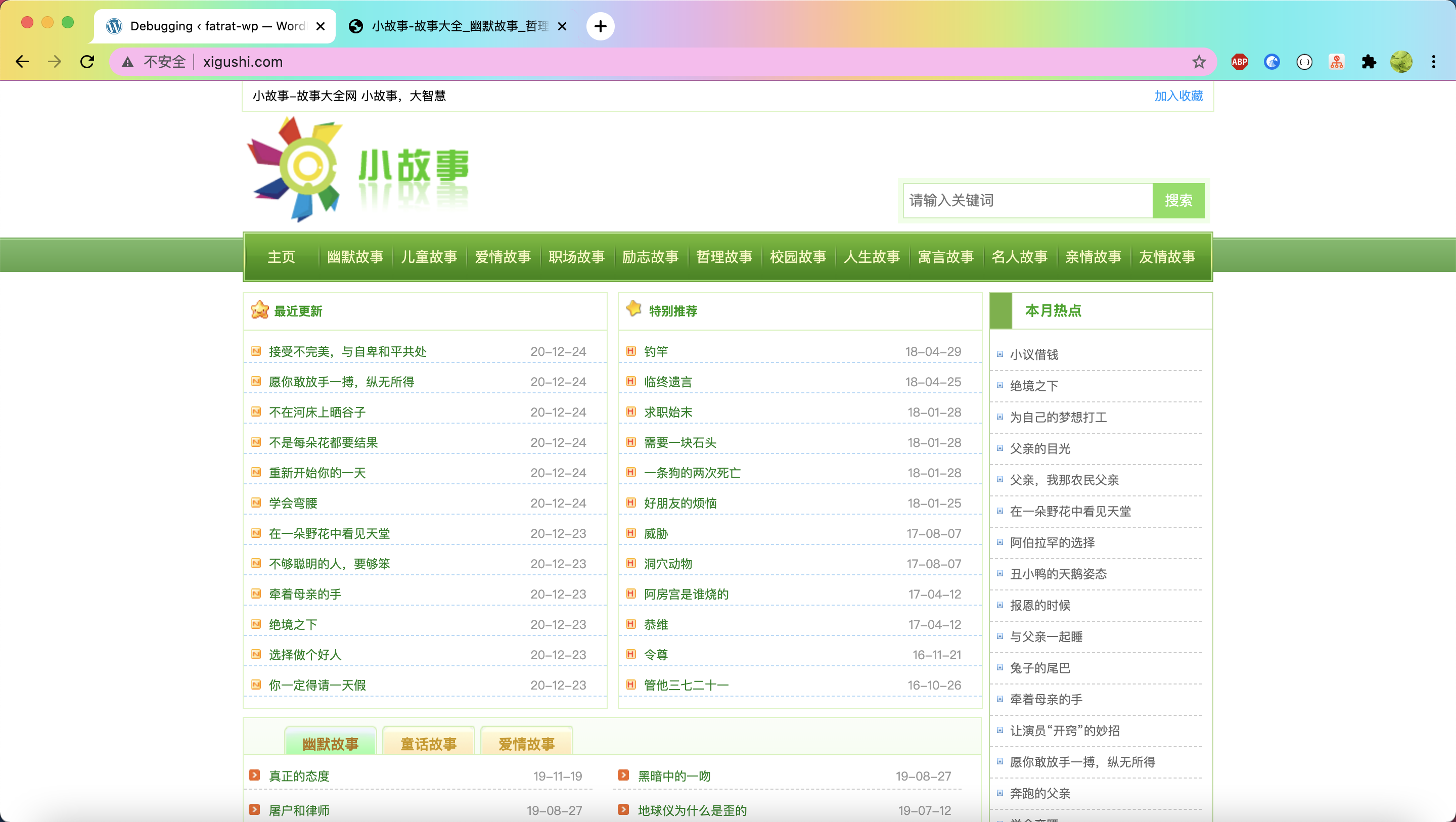 右键查看网页源代码:找到它所有故事详情页url
右键查看网页源代码:找到它所有故事详情页url
注意他的故事详情页地址是相对路径:但是胖鼠采集采集时自动补全他的链接地址
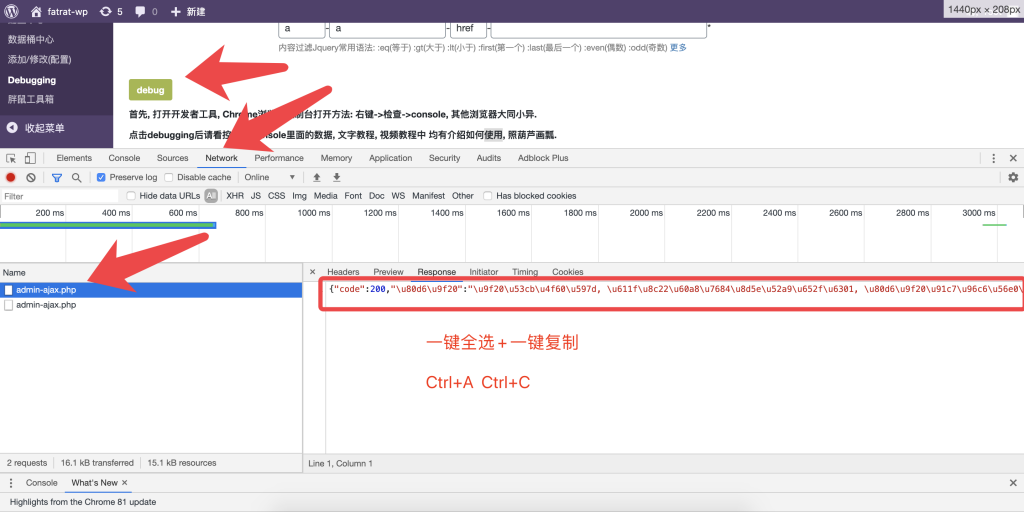
 在源代码页面 Ctrl+A(全选) Ctrl+C(复制)
在源代码页面 Ctrl+A(全选) Ctrl+C(复制)
打开在线正则表达式网站 https://tool.oschina.net/regex
Ctrl+V(粘贴进去)
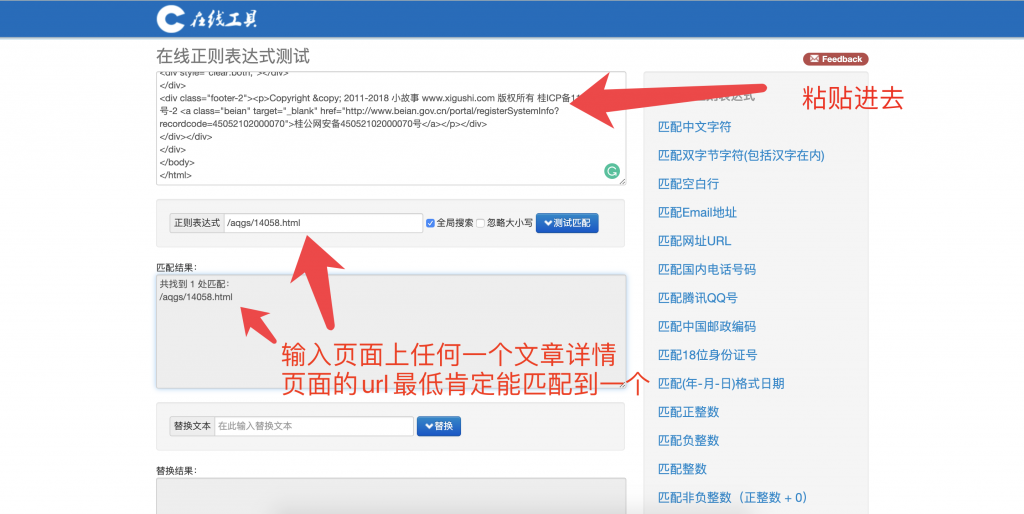 能匹配到一个并不是我们的目标。我们的目标是匹配到页面上所有文章详情的url
能匹配到一个并不是我们的目标。我们的目标是匹配到页面上所有文章详情的url
然后我们改改正则表达式的规则
原先是这样的 /aqgs/14058.html
我们先来修改后面的数字使用 \d+(\d是匹配数字的意思 +最少出现一次)
修改后是这样的 /aqgs/\d+.html
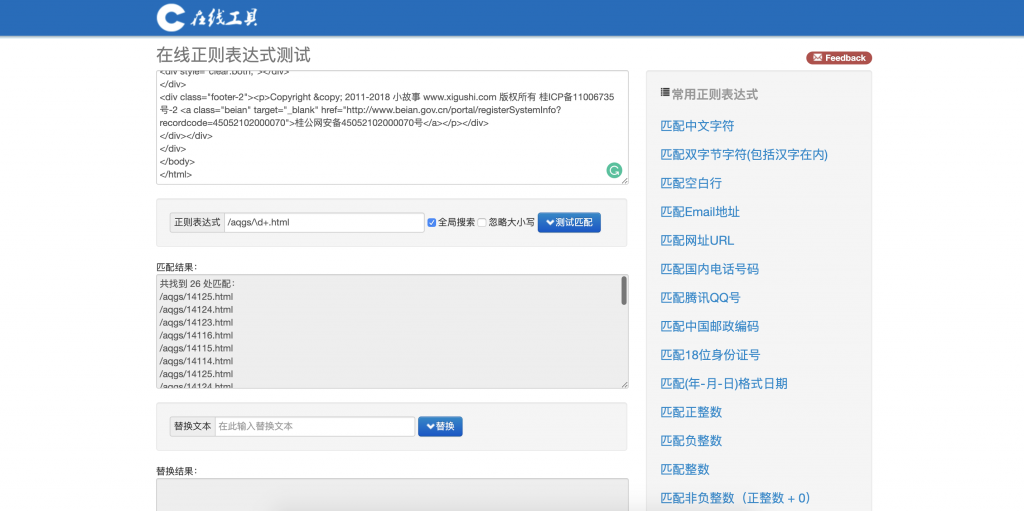 看我们匹配到了 26 个这个频道的链接。
看我们匹配到了 26 个这个频道的链接。
然后我检查后发现其他频道和这样频道模板是一样的。
说明详情规则可以共用,那就再优化一下正则把
修后后是这样的 /aqgs/\d+.html
我们先来修改前面的的字符 \w+(\w是匹配文本或者数字或者下划线的意思 +最少出现一次)
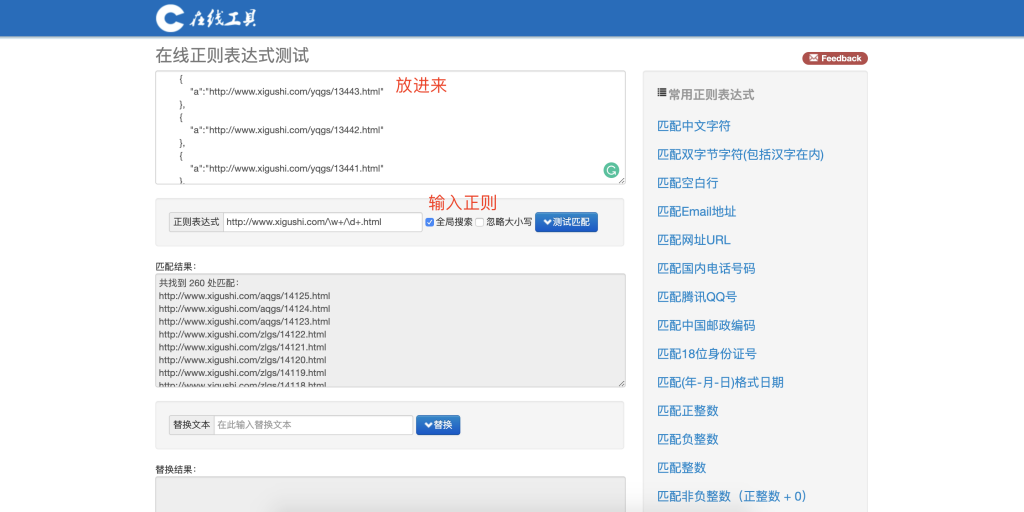
再次修改后是这样的 /\w+/\d+.html
 好的,我们成功匹配到了 260个 文章链接,现在可以写规则了
好的,我们成功匹配到了 260个 文章链接,现在可以写规则了
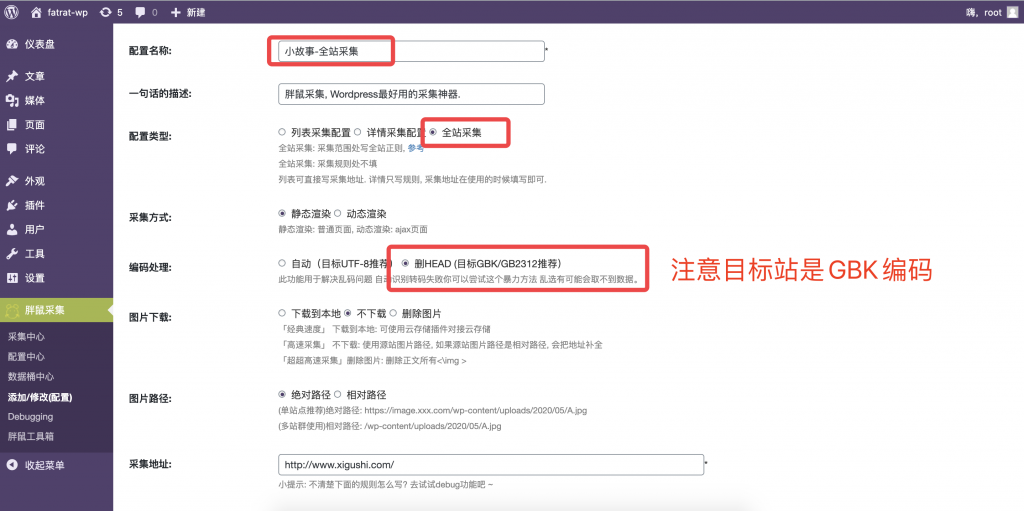
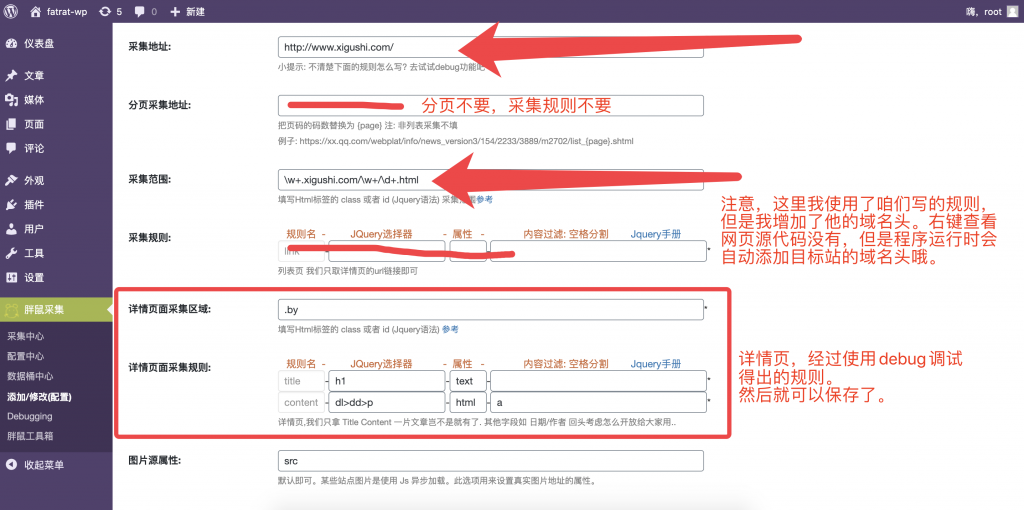 注:如果想要测试匹配已经加过域名头的URL,可以这样操作。
注:如果想要测试匹配已经加过域名头的URL,可以这样操作。
保存后去运行
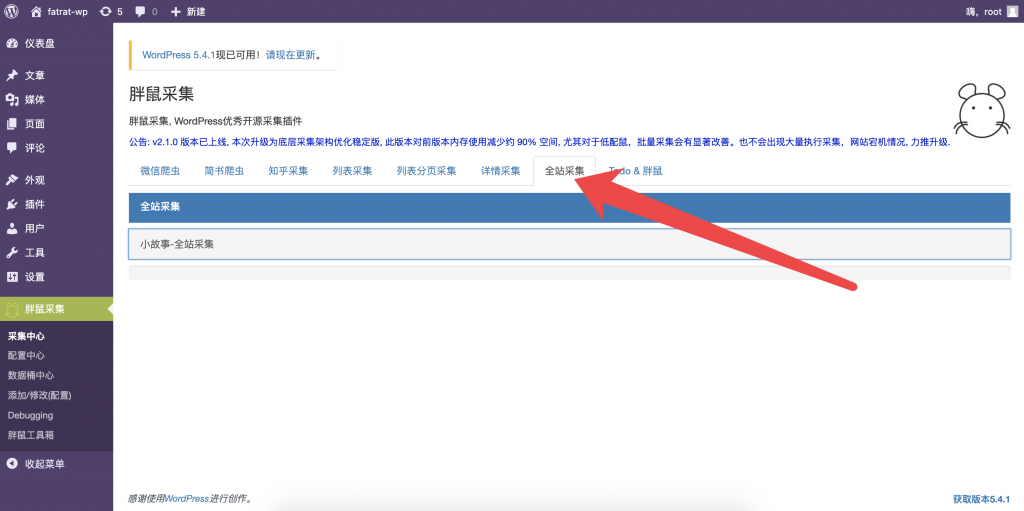
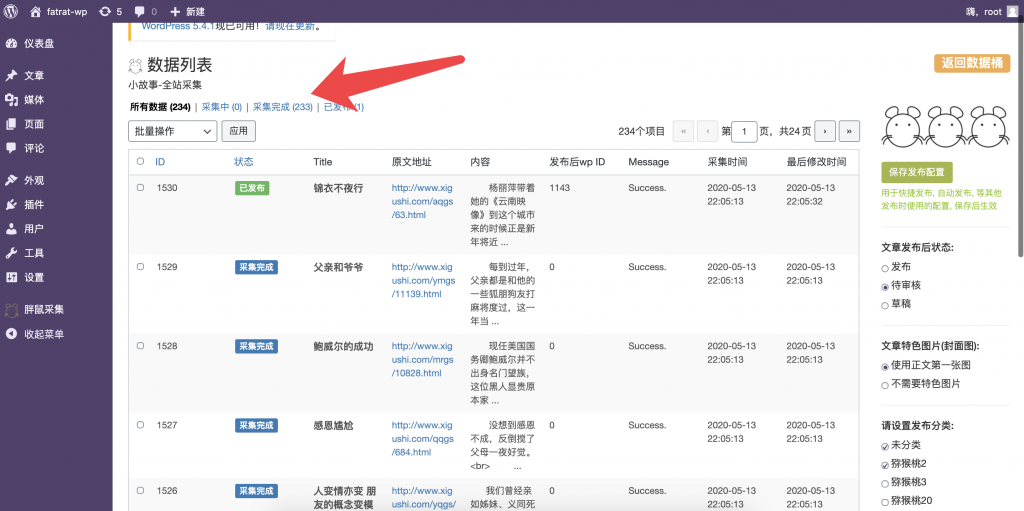 后续全站采集增加详细的定时采集功能,可用于实时监控目标网站,首页或者复杂页面的,多个热更新数据块。采集过会滤重哦。
后续全站采集增加详细的定时采集功能,可用于实时监控目标网站,首页或者复杂页面的,多个热更新数据块。采集过会滤重哦。
当然,这是胖鼠对这个功能的理解。大家可以根据需求更加灵活运用喔。
注:如果想要测试匹配已经加过域名头的URL,可以这样操作。


 最终结果啦。这样可以获取到正确的正则哦
最终结果啦。这样可以获取到正确的正则哦
关于正则的语法。诸位站长鼠应该不陌生,
如果有不了解的可以搜索: 正则表达式语法
{success} 先这样啦,拜拜。